In 2017, I ran a small set of experiments that asked the question: if the US Senate demographics were the results of a fair process, how (un)likely would the 2017 US be? Spoiler alert: not very likely to come from a fair process in 2017.
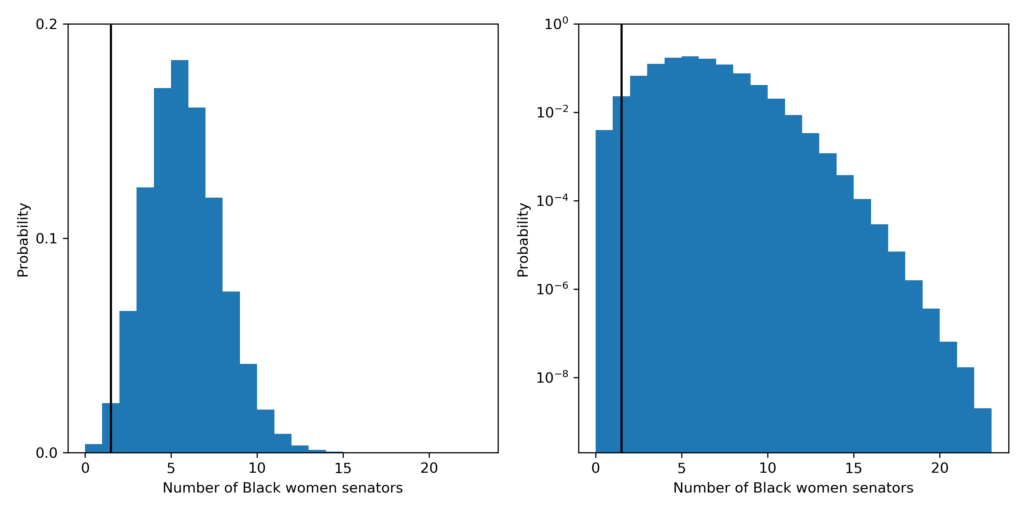
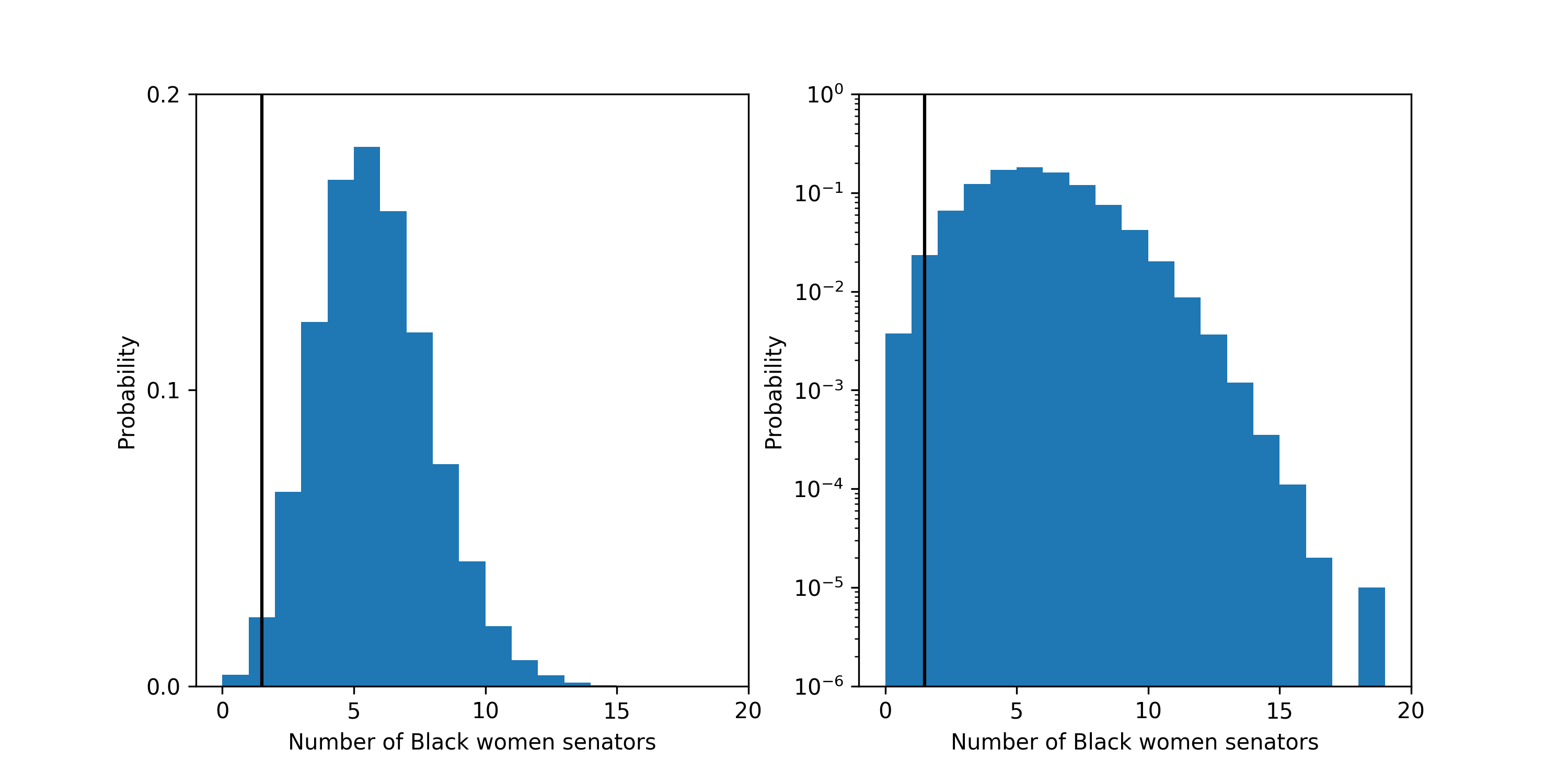
First, let’s look at what the probability is that a fair process produced a Senate with 1 or fewer Black women senators. The probability is about 2.7 in 100. The most likely outcome predicted by a fair process is 5 Black women senators which should happen 18% of the time.
The probability distribution for the number of Black women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black women: 1, in the Senate.
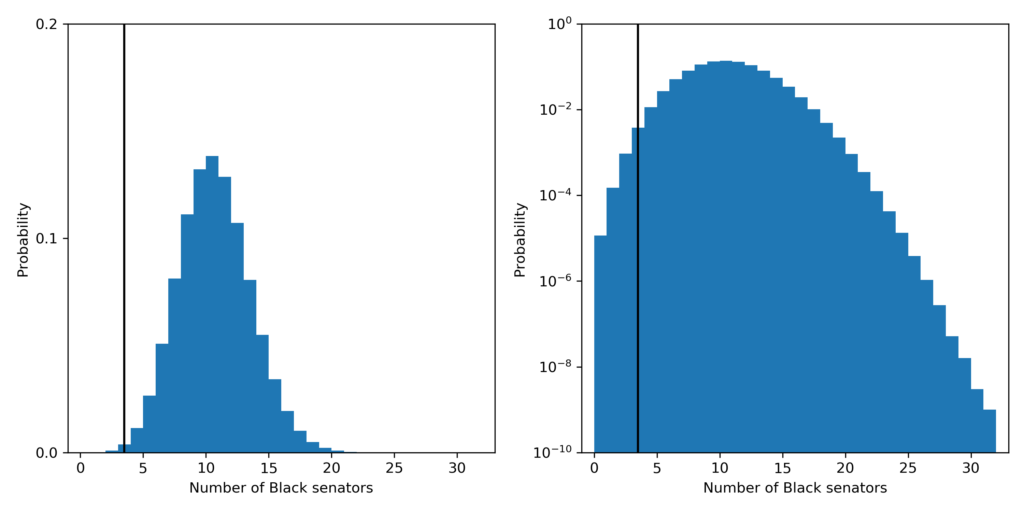
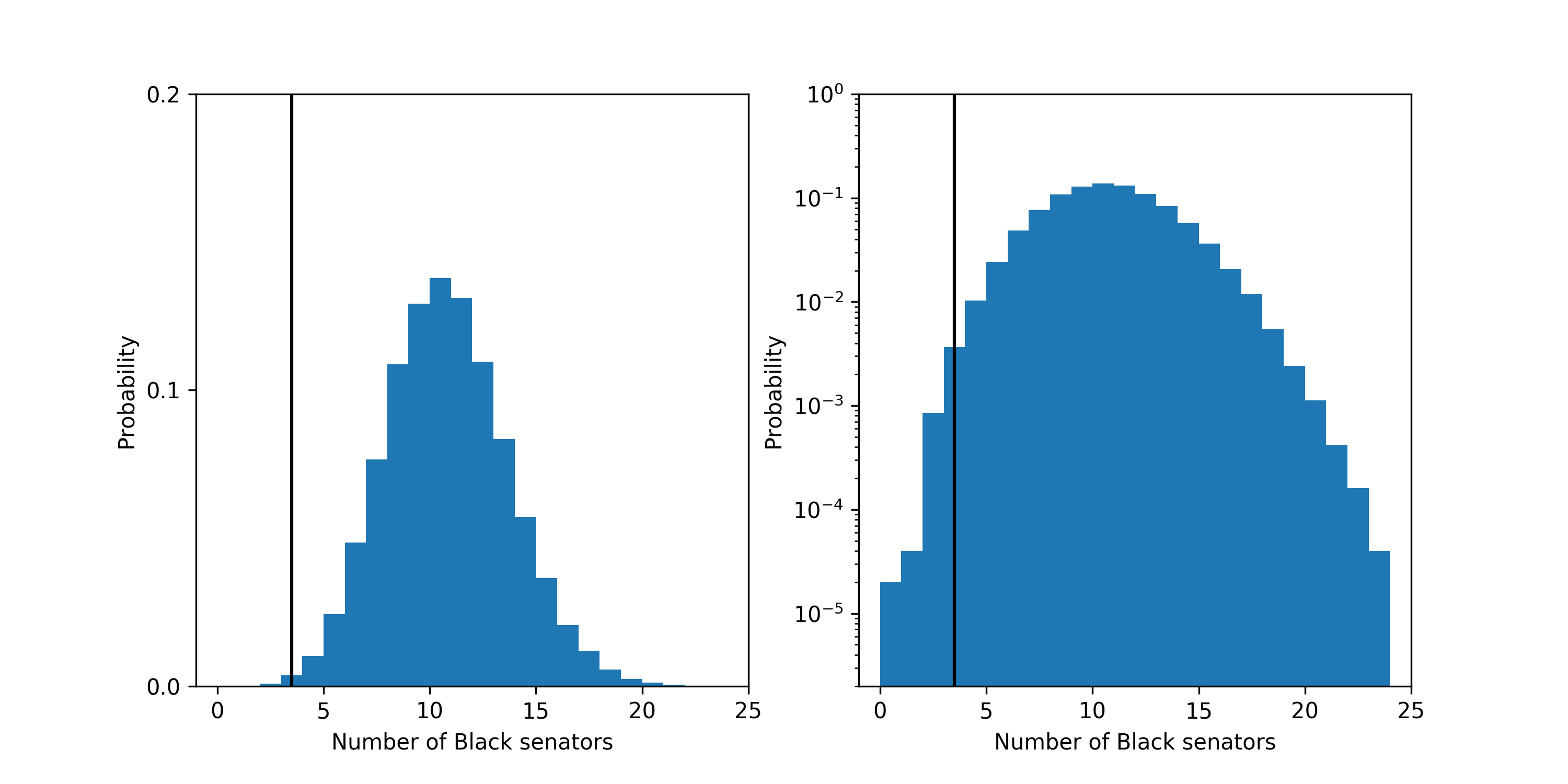
The probability that a fair process led to a Senate with 3 or fewer Black senators is about 4.9 in 1,000. The most likely outcome predicted by a fair process is 10 Black senators which should happen about 14% of the time.
The probability distribution for the number of Black senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black people: 3, in the Senate.
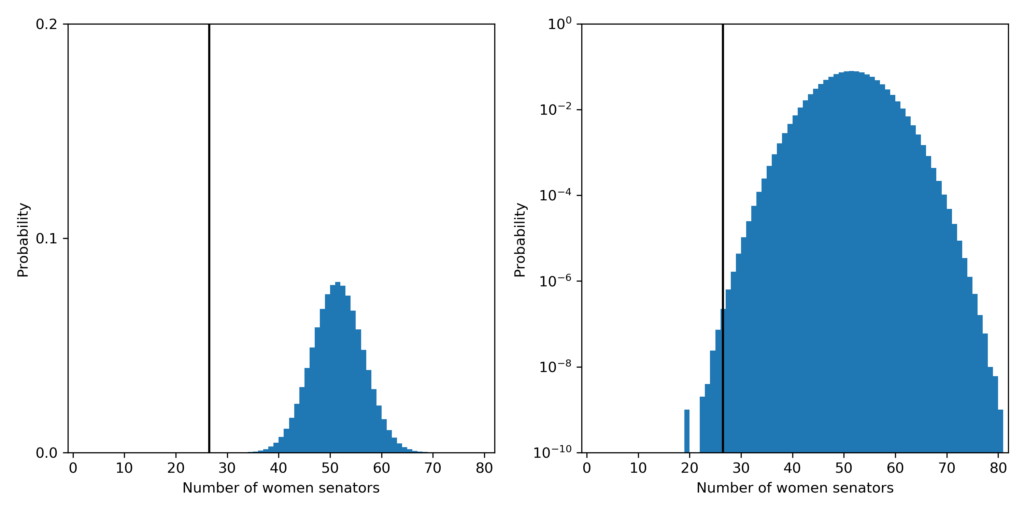
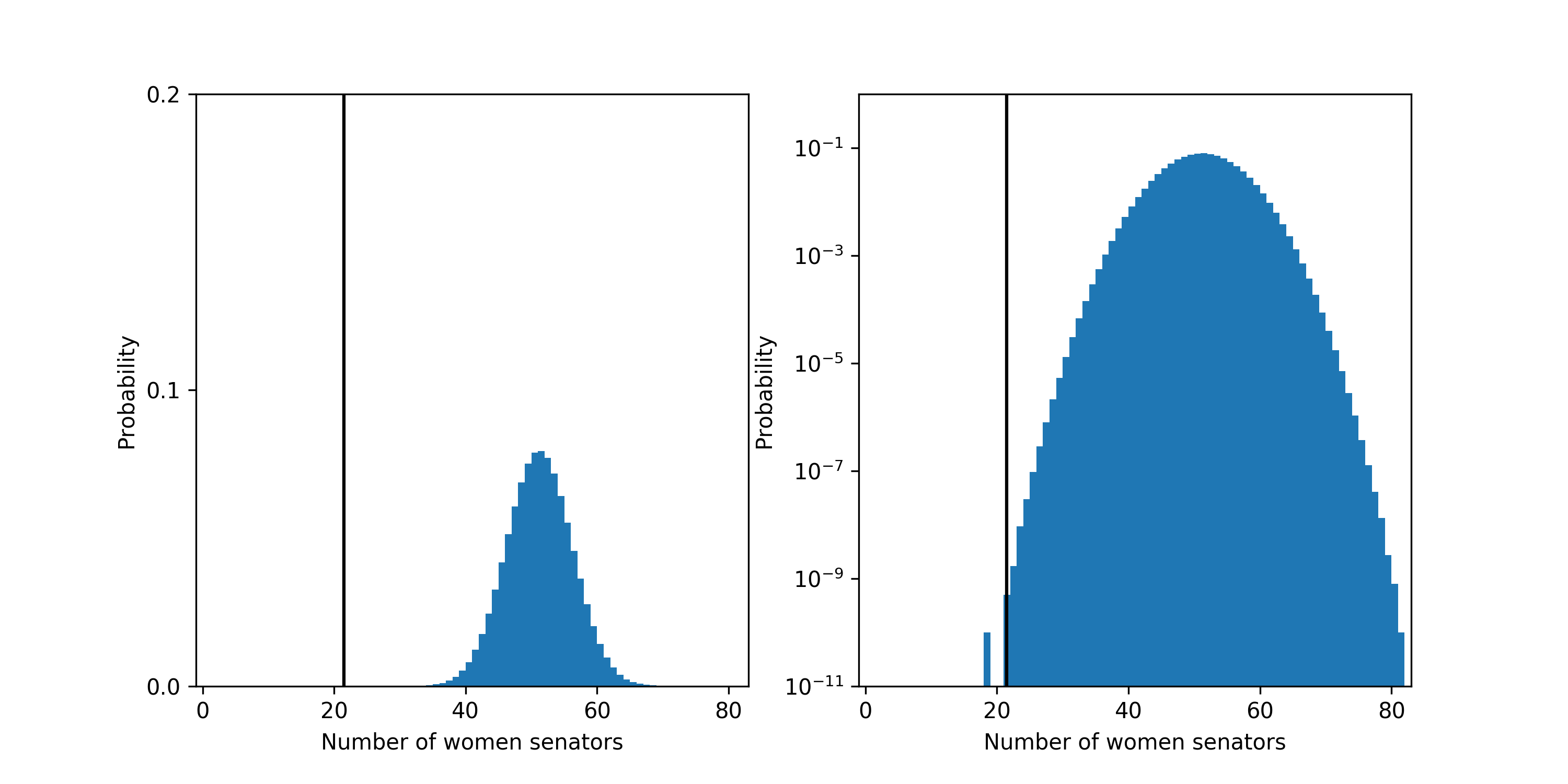
The probability that a fair process led to a Senate with 26 or fewer women senators is about 3 in 10,000,000! The most likely outcome predicted by a fair process is 51 women senators which should happen about 8% of the time.
The probability distribution for the number of women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of women: 26, in the Senate.
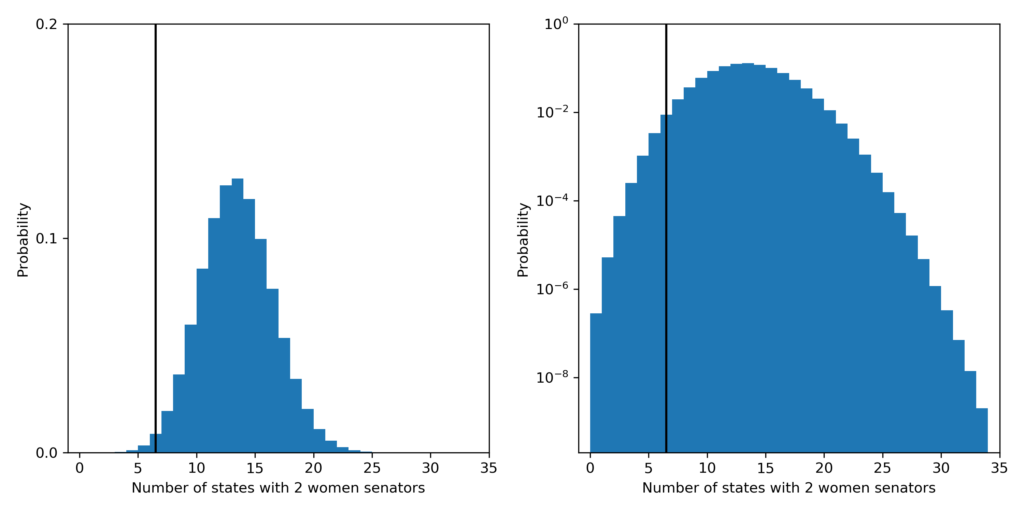
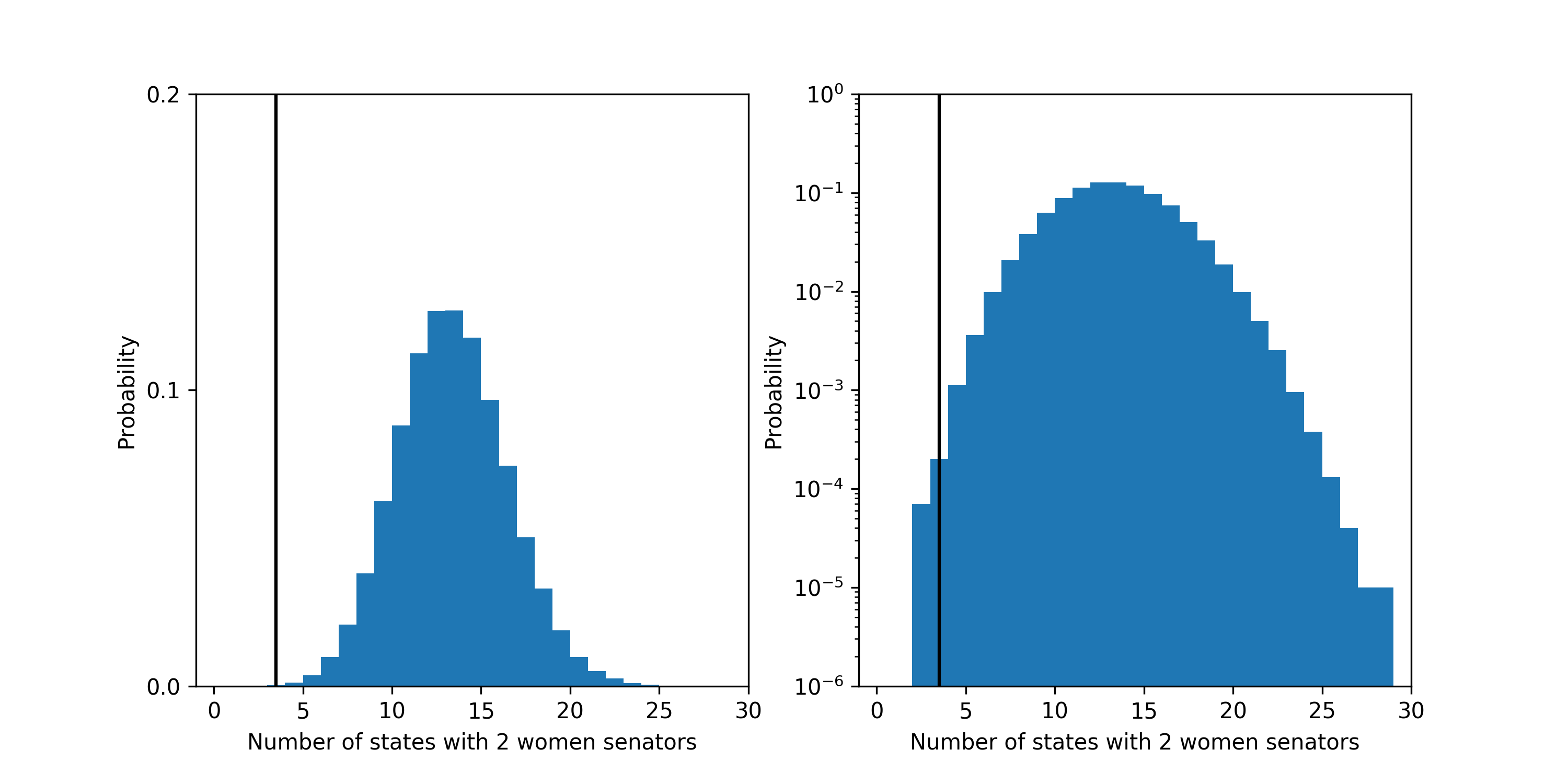
Finally, the probability that a fair process led to a Senate with 3 or fewer states with 2 women senators is about 1.3 in 100. The most likely outcome predicted by a fair process is 13 states with 2 women senators which should happen about 13% of the time.
The probability distribution for the number of states with 2 women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of states: 6, in the Senate.
So what’s changed? Broadly, this shows that becoming a US Senator is not a fair process. It it biased against non-Black women, Black people and Black women. The number of women has significantly increased, but is still not close to a fair fraction. The number of Black senators and Black women senators has not changed. Still more work to do!
You can find the data and code to reproduce these plots here.
Do we in the US still have the same Senate as it existed in 1790 (first census)? I’ll attempt to answer this question with regards to one particular attribute: the division of senators by percentiles of the population. Unlike the House, the Senate is not meant to represent states proportional to their population; each state gets 2 senators. When this system was created, the states had some distribution of large and small populations. Over time, the number of states and their populations have changed.
When the Senate was created, it was known that it would represent states but not individuals equally. This might be a reasonable system if the states’ populations are not too skewed [1]. It does become an obviously ridiculous system in the skewed limit. If a state lost enough residents such that its population became 2, it would be pretty bizarre to have them both as senators and have one senator represent one person’s vote. How skewed are we and has this changed since the late 1700s?
A simple way of answering this question is to break the US’s population into percentiles by how many senate votes they have. We’ll do this for four percentiles: 0-25%, 25-50%, 50-75%, and 75-100%. 0-25% percentile is the 25% percent of the population which has the largest fraction of a Senate vote, i.e. the 25% of the US population from the states with the smallest populations. This same process applies for the next 3 percentiles. If we know the population of the states [2] over time (available through the census), we can calculate the percentiles.
What does this look like for the 1790 through 2010 censuses?
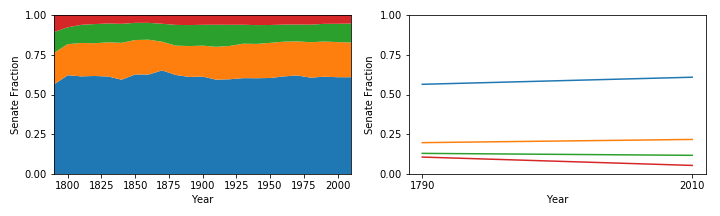
The plot on the left shows the four percentile divisions over time since the 1790 census. The plot on the right is lines connecting the fractions per division (not stacked) for 1790 and 2010 only.
The large blue area is the fraction of Senate seats going to the top 25% of the population (most Senate representation). It has hovered just over 60% of the Senate vote and has increased about 4% from 1790 to 2010 (much of that happened in the first decade).
The next orange and green areas show the next two percentiles which have increased by 2% and decreased by 1% respectively.
The small red area is the fraction of Senate seats going to the bottom 25% of the population (least Senate representation). It has hovered around 5% of the Senate vote and has decreased about 4% from 1790 to 2010 (much of that happened in the first decade).
This means that the top and bottom 25%s of the country currently have a 10x disparity in Senate representation.
And over time, the 50% of people who live in the smallest states, i.e. have the most Senate representation, have about 6% more voting power (equivalent to 6 more senators) in the Senate compared to 1790. Conversely, the 50% of people who live in the largest states, i.e. have the least Senate representation, have lost about 6% (lost 6 senators). I’ve rounded to whole numbers, so things don’t exactly add up as I’ve presented.
Recent trends
These percentiles move around a lot in the first 100 years of the US and those trends probably are not still happening today. What about if we look at the last 50 years?
In the last 50 years, the 50% of the population with the most representation in the Senate (smallest states) have had no significant change in representation. The 25% of the population with the least Senate representation have lost about .2% of a Senate seat per decade and the 25% with the second least representation have gained about .3% of a Senate seat per decade.
So the two main conclusions are one: that there is a large degree of skewness (~10x) in Senate representation, and two: that this has been relatively stable except for the 25% of the population with the least Senate representation (largest states) which has lost about half of its representation since 1790.
Notes
[1] I’m not commenting here on whether having the Senate as a congressional body is or was a good idea, just whether that body has changed over time in this particular way.
[2] I’ve removed the enslaved population in states since they had no representation.
Code to reproduce these plots (and more!) can be found here.
At first glance, it looks like the demographics of the US Senate are not representative of the US as a whole; the demographic percentages are not very similar to the Senate percentages. But how can we check this quantitatively? The p-value, a simple metric coined by statisticians, is commonly used by researchers in science, economics, sociology, and other fields to test how consistent a measurement or finding is with a model of the world they are considering.
It’s important to note that this is an overly simplistic picture of demographics. This categorization of gender and race leaves out many identities which are common. This simplified demographic information happens to be easy to come by, but this analysis could easily be extended to include more nuanced data on gender and race, disability identity or sexual orientation, or other factors like socio-economic background, geography, etc. if it is available for the Senate and the state populations.
First, a bit of statistics and probability background.
Randomness and biased coin flips
In many domains (physics, economics, sociology, etc.) it is assumed that many measurements or findings have an element of randomness or unpredictability. This randomness can be thought of as intrinsic to the system, as is often the case in quantum mechanics, or as the result of missing measurements, e.g. what I choose to eat for breakfast on Tuesday might be more predictable if you know what I ate for breakfast on Monday. Another simple example is a coin flip: if the coin is “fair” you know that you’ll get heads and tails half of the time each, but for a specific coin flip, there is no way of knowing whether you’ll get heads or tails. It turns out that sub-atomic particle interactions, what you buy at the supermarket on a given day, or who becomes part of your social circle all have degrees of randomness. Because of this randomness, it becomes hard to make exact statements about systems that you might study.
For example, let’s say you find a quarter and want to determine whether the coin was fair, i.e. it would give heads and tails half of the time each. If you flip the coin 10 times, you might get 5 heads and 5 tails, which seems pretty even. But you might also get 7 heads and 3 tails. Would you assume that this coin is biased based on this measurement? Probably not. One way of thinking about this would be to phrase the question as: what are the odds that a fair coin would give me this result? It turns out that with a fair coin, the odds of getting 5 heads is about 25% and the odds of getting 7 heads is about 12%. Both of these outcomes are pretty likely with a fair coin and so neither of them really lead us to believe that the coin is not fair. Try flipping a coin 10 times; how many heads do you get?
Let’s say you now flip the coin 100 times. The odds of getting 50 heads is about 8%. But the odds of getting 70 heads is about .002%! So if you rolled 70 heads, you would only expect that to happen 2 out of every 100,000. That’s pretty unlikely and would probably lead you to believe that the coin is actually biased towards heads.
This quantity: the odds that a model (a fair coin in this example) would produce a measurement or finding (70 heads in this example) is often called a p-value. We can use this quantity to estimate how likely it is that the current US Senate was generated by a “fair” process. In order to do that, we’ll first need to define what it means (in a probabilistic sense) for the process of selecting the US Senate to be “fair”. Similarly, we had to define that a “fair” coin was one that gave us equal odds of heads and tails for each toss. Now you can start to apply this tool to the Senate data.
What is “fairness” in the US Senate
I’m going to switch into the first person for a moment since the choices in this paragraph are somewhat subjective. I have a particular set of principles that are going to guide my definition of “fair”. You could define it in some other way, but it would need to lead to a quantitative, probabilistic model of the Senate selection process in order to assess how likely the current Senate is. The way I’m going to define “fair” representation in the US Senate comes from the following line of reasoning. I believe that, in general, people are best equipped to represent themselves. I also believe that senators should be representing their constituents, i.e. the populations of their states. Taking these two things together, this means that I think that the US Senate should be demographically representative on a per-state basis. I don’t mean this strictly such that since women are 51% of the population there should be exactly 51 women senators, but in a random sense such that if a state is 51% women, the odds of electing a woman senator should be 51%. See the end of this post for a few assumptions this model makes.
Given this definition of “fair”, we can now assess how likely or unlikely is it that a fair process would lead to the Senate described above: 1 Black woman senator, 3 Black senators, 21 women senators, or 3 states with 2 women senators. To do this we’ll need to get the demographic information, per state, for the fraction of the state that is women and Black. I’m getting this information from the 2010 Census. It is possible to calculate these probabilities exactly, but it becomes tricky because, for instance, there are many different ways that 21 women could be elected (there are about 2,000 billion-billion different ways), and so going through all of them is very difficult. Even if you could calculate 1 billion ways per second, it would still take you, 60,000 years to finish. If we just want a close approximation to the probability, we can use a trick called “bootstrapping” in statistics. This works by running many simulations of our fair model of the Senate and then checking to see how many of these simulations have outcomes like 21 women senators or 3 Black senators. Depending on how small the probabilities we are interested are, we can often get away with only running millions or billions of simulations, which seems like a lot but is much easier than having to do many billion-billion calculations and can usually be done in a matter of minutes or hours.
The core process of generating these simulations is equivalent to flipping a bunch of biased coins. For each state, we know the fraction of the population which are women and/or Black. So, for each of the two Senate seats per state, we flip two coins. One coin determines gender and the other race. We can then do this for all 50 states. Now we have one simulation and we can check how many Black women senators or states with 2 women senators, etc., we have. We can then repeat this process millions or billions of times so that we can estimate the full distribution of outcomes. Once we have this estimated distribution, we can check to see how often we get outcomes as far away or further from the expected average.
So, what are the odds?
So what do the results look like? I’m going to present two plots side-by-side which show the same information in two ways. The plots on the left will show the distributions of expected outcomes the fair process predicts as blue histograms and where the current Senate value falls in that distributions as a black vertical line. The plots on the right will show the same information with the y-axis log-scaled. This will make it easier to see very small probabilities, but also visually warps the data to make small probabilities appear larger than that really are. If you’re not used to looking at log-scale plots, the plot on the left gives the clearest picture of the data. Data and code to reproduce these figures can be found here.
First, let’s look at what the probability is that a fair process produced a Senate with 1 or fewer Black women senators. The probability is about 2.7 in 100. The most likely outcome predicted by a fair process is 5 Black women senators which should happen 13% of the time.
The probability distribution for the number of Black Women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black women: 1, in the Senate.
The probability that a fair process led to a Senate with 3 or fewer Black senators is about 4.6 in 1,000. The most likely outcome predicted by a fair process is 10 Black senators which should happen about 14% of the time.
The probability distribution for the number of Black senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black people: 3, in the Senate.
The probability that a fair process led to a Senate with 21 or fewer women senators is about 6 in 10,000,000,000! The most likely outcome predicted by a fair process is 51 women senators which should happen about 8% of the time.
Finally, the probability that a fair process led to a Senate with 3 or fewer states with 2 women senators is about 3 in 10,000. The most likely outcome predicted by a fair process is 13 state with 2 women senators which should happen about 13% of the time.
The probability distribution for the number of states with 2 women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of states: 3, in the Senate.
These odds together show that it is very unlikely that the process for selecting US senators is fair according the the definition I have chosen. Now the question becomes: how does this disparity arise?
There is a wealth of evidence that shows how this comes about, such as segregation in schools and housing, unequal access to employment and social networks, gerrymandering, racial discrimination in voting through voter ID laws, and the repeal of portions of the voting rights act, just to name a few.
Nate Silver did a bit of analysis to trying to understand this (thanks for the reference, Peter). In 2009, he wrote a post titled: Why Are There No Black Senators? The main finding is that there is a nonlinear relationship between district demographics and House representative demographics. If a district is less than about 35% Black, the district has a lower probability of electing a Black rep. than would be expected by demographics. Conversely, if a district is more than about 35% Black, it is slightly more likely to elect a Black representative than would be expected by demographics. Unfortunately, I think he does a fairly bad job at trying to explain the finding, but the finding itself is interesting.
Silver then asks whether these racial biases in House voting patterns can explain the lack of Black senators.
They essentially do. Since states are more homogeneous than House districts, the fraction of state populations that are Black are much smaller than 35%. In fact, only one state has more than a 35% Black population (Mississippi at 37%). This means that Silver’s model predicts that there should only be about 1 Black senator, which is consistent with the 0 Black senators at the time and the 3 Black senators now. That data wasn’t published with the article, so it’s hard to say what the exact odds of 0 or 3 would be, but approximating it as a Poisson distribution gives 30% and 10% respectively.
Another way of trying to get at this question is to split the process of becoming a senator into two parts and look for bias in the parts individually. The first is the path that leads people to becoming candidates for Senate seats and the second is the election process which choses senators from this pool. This data is not easily available on the internet as far as I can tell (Let me know if that’s not true!), but would shed more light on where the biases are coming in to the process.
Assumptions and comments
A few assumptions that I am making:
the 2010 demographics are similar to the demographics of today,
the product of the gender and race fractions give the gender-race fractions per state,
the census demographics are similar to the demographics of those eligible to be a senator per state, and
that all senators are elected at once.
I’ve compared assuming flat demographics across states and the data that I use above and the p-values fluctuated up or down about a factor of 2 or 3. If I could get data that doesn’t make the above assumptions, I wouldn’t expect anything to change by more than another factor of 2 or 3 up or down.
Edit: The 6 in 10,000,000,000 statistic is probably not super accurate since it happens so rarely (it’s way out in the tail of the distribution). I’m confident that it is smaller than 1 in 100,000,000 but wouldn’t claim the number I’m reporting is super accurate.
And a comment:
The statement “I believe that, in general, people are best equipped to represent themselves” needs a bit of unpacking. I would probably add the condition that, given equal access to resources, people are generally best equipped to represent themselves. I also think the idea that “some people are intrinsically more likely to want to be a senator” is kind of the reverse of the way I’m looking at the problem. Representatives and senators should represent their constituents. Given that I also think that people are best equipped to represent themselves, the jobs of Congress should be adapted so that more people could fulfill them. Congress already receives a ton of support from staff and experts, so it is not clear to me that it requires a particular set of skills or level of expertise apart from the intention to represent your constituents.
Thanks to Sarah for edits and feedback! Thanks Mara, Papa, and Dimitri for catching some typos!
The electoral college (EC) is the system used in the US to determine how individual’s votes for president get turned into the numbers that actually determine who becomes president. Each state and D. C. is allocated a number of electors based partially on the population of the state from the last census. The number of electors is equivalent to the number of senators + the number of representatives for each state (D. C. gets 3), see here for details about how the allocations are calculated.
I’ve heard people say that one of the things the EC does is prevent voters in the cities from dominating rural voters. This has always seemed a bit odd to me since, on its face, the allocation is just based on state populations and not demographics. So, I decided to look at the relationship between rural, urban, and total population and how they related to the number of electoral college votes. The code and data for reproducing the plots are here. This is all based on 2010 Census data.
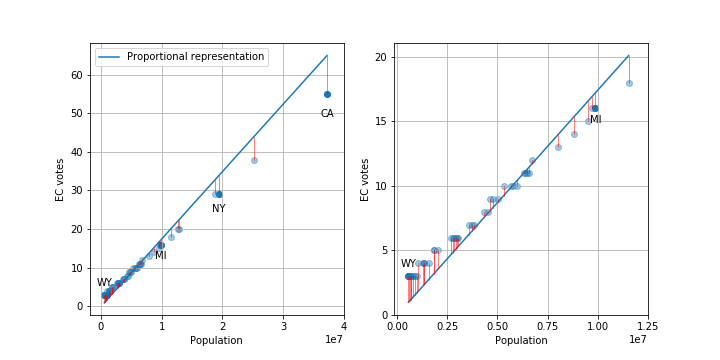
OK, first let’s just look at how many EC votes each state gets. There are a total of 538 electors. The plot below shows the distribution of votes for each state along with a line showing the number each state would be allocated if it was done exactly proportional to population. I’ve labeled a few states of interest.
Plots of the number of electoral college votes per state. Plot on the right in an inset of the bottom left corner of the plot on the left. Blue line is the number of votes states would have if the number of votes was proportional. The red vertical lines are the differences between the proportional number and actual number. (click to get larger version)
As you can see, states with smaller populations tend to have larger than proportional representation and larger states have fewer votes.
We can look at the number of electoral votes that different people get, i.e. how much is your vote worth in a presidential election. I’m leaving out a lot of important details, like racist voter suppression, the number of actual people able to vote in each state versus total population, and changes in population/demographics since 2010. Given the 538 electors and the 2010 population of 308,745,538, the average person gets. 1.7e-6 or 1.7 millionths of a vote. But, this will vary state-to-state based on the number of electors allocated to each state.
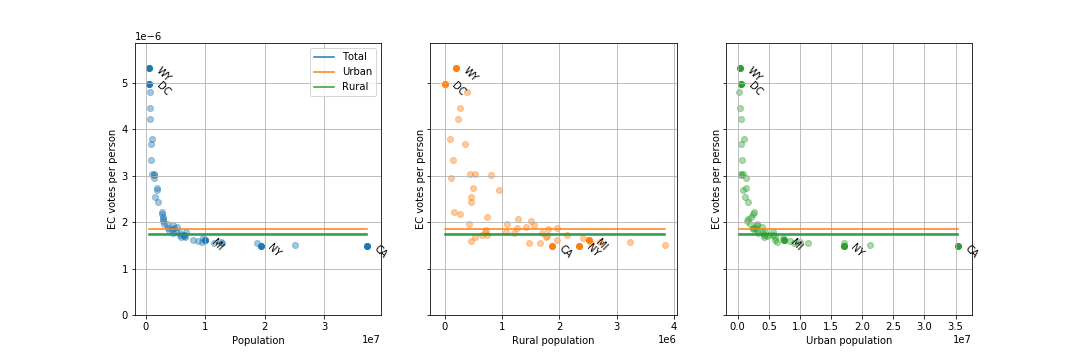
EC votes per person for different states and D.C.. Plotted against total state population, rural population, and urban population (rural and urban add up to total). (click to get larger version)
As you can see, the number of EC votes per person varies from about 1.5 millionths (California) to 5.3 millionths (Wyoming), about a factor of 3.5. State with populations above about 10 million all have similar EC votes per person, but small states can have much larger votes per person.
The solid blue line is the national average EC votes per person (1.74 millionths), the solid green line is the national average EC votes for someone living in a urban area (1.72 millionths, barely below the blue line), and the solid orange line is the national average EC votes for someone living in a rural area (1.85 millionths). So, on average, a person living in a rural area has about 8 percent more voting power compared to someone living in an urban area.
But!, the 601,723 people living in urban D. C. have 338 percent more voting power than the 1,880,350 people living in a rural area of California.
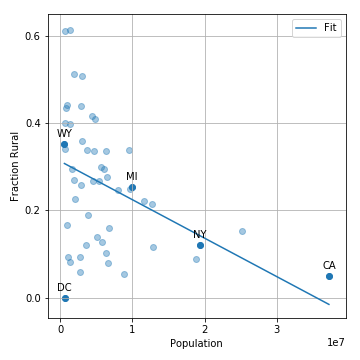
Finally, let’s look at how the total state population correlates to the fraction of people living in rural areas.
Fraction of population which lives in rural areas versus total population. There is a trend that states with larger populations tend to have a smaller fraction of people living in urban areas. For states with a total population less than than 10 million, there is much more variance in the fraction of people living in urban areas.
This shows that there is indeed a negative correlation, i.e. smaller states tend to have more people living in rural areas (this leads to the 8 percent difference above).
The thing that I take away from all of this is that the electoral college is actually weighting your vote as a member of the US lower than your vote as member of your state. Because of the current state demographics, it also weights rural votes slightly higher than urban votes, but this is a very small effect compared to the small state versus large state effect (8 vs. 350 percent). So, if you currently live in a big city in California, New York, or Texas and want your vote for president to have more impact, you’ll get more value for your vote if you move to an urban area in Wyoming, D. C., or Vermont rather than a rural area of your state, although you can still have an impact on House and state reps within your state.
I should also note that all of this analysis misses a larger problem of the electoral college: most states have a winner-take-all system where the candidate with the popular majority takes 100 percent of the electoral votes. This means that a candidate who wins 51 percent of the votes in a state gets 100 percent of the EC votes. This system is also used for state reps. and when coupled with gerrymandering, can lead to skews in the state representation compared to state voting demographics.
Edit: Thanks Dylan for catching some spelling errors!
I started this series of posts to understand why the weather in the Bay Area seems different than weather in the places I’ve previously lived. In this post, I’ll show one analysis that I think answers this question. As a reminder, in part 1, I showed some basic visualization of the raw data and an annual summary. In part 2, I went over two analyses that showed that the Bay Area has different weather as compared to Detroit and Ithaca, but neither really got at the heart of why my experience was different.
In this post I’ll present two more analyses. The first shows another interesting difference between the Bay Area and Detroit and Ithaca. The second post really gets at the question that I’ve been trying to answer and introduces the jacket crossing probability (something I made up).
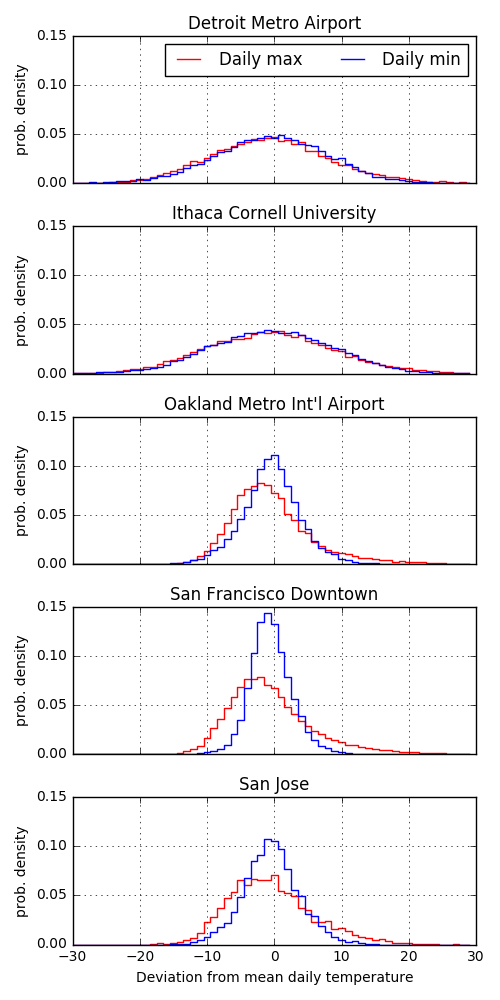
Based on the power-spectrum analysis in part 2, I decided to look in more detail at the daily fluctuations (right side of the plot). For any given day of the year in a city, say May 17th, there is an average temperature, maybe 70 degrees. In addition to the average, there are also the year-to-year fluctuations. These fluctuations can be averaged over all days in a year and plotted.
Again, the Bay Area looks very different than Detroit and Ithaca. The distributions of daily high and low fluctuations for Detroit and Ithaca both look very symmetric and fairly Gaussian. The fluctuations have a standard deviation of about 15 degrees and look almost identical for the daily highs and lows. In contrast, the Bay Area distributions are much narrower, with standard deviations less than 10 degrees for all highs and lows. The daily highs tend to have their modes skewed towards lower temperature with longer tails into the highs. The daily low temperatures tend to be more symmetric and have smaller standard deviations. This means that each day’s daily high or low is more predictable in the Bay Area.
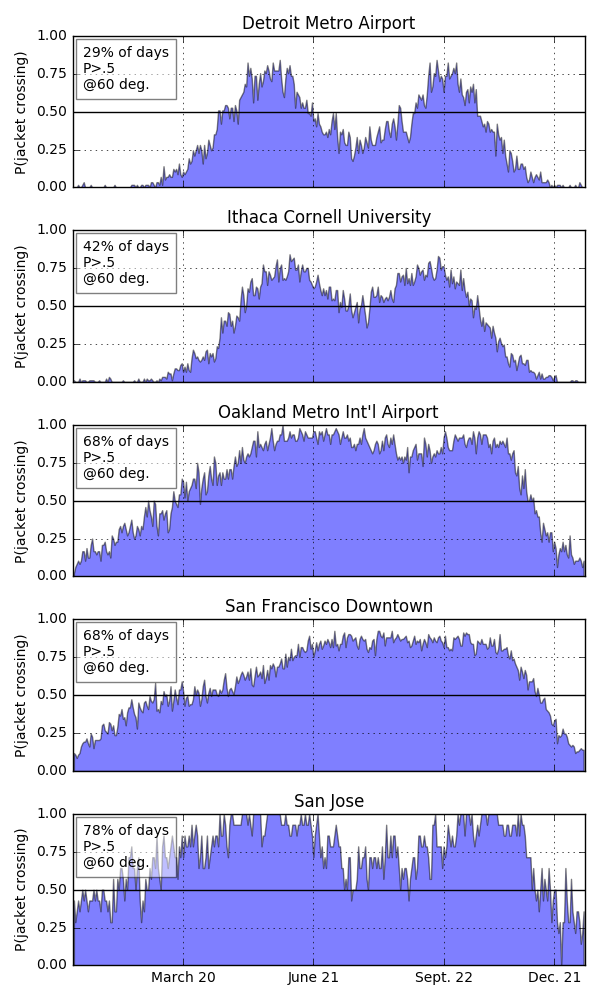
Now, to really get at the question of why the Bay Area’s weather is weird I came up with a metric I’m calling the jacket crossing probability: for a given day, what are the odds that the daily high is above and temperature where I’d want a jacket and the daily low is below that temperature. We can plot this probability for all days.
I personally need a jacket when it gets below 60 degrees. If I set this as the threshold, I get the above jacket crossing probabilities. So, Detroit and Ithaca only have two relatively short periods where, with greater than 50% odds, you’ll both want and not want a jacket. They align with late spring and late fall. Similar periods for Oakland and San Francisco extend from spring through summer and into fall. In San Jose, this period extends for almost the entire year outside. So, in the Bay Area, the annoying time when you might both want and not want a jacket extends for the better part of the year. In Detroit and Ithaca, summers are hot and winters are cold and you can prepare for the entire day easily. I think these plots really get at the differences in weather I’ve experienced in the Bay Area.
I’ll follow up with maybe one more post with some additional analyses that others have suggested or done themselves (yay for collaboration!).
In part 1, I showed some raw temperature data for a few different cities I’ve lived in. I also had a plot of the daily average temperature over a year for the cities. Code for making the plots are here.
The goal of this project is to try and understand why my perception of the weather in the Bay Area is so different from other places I’ve lived. This post will start to look into the question of daily temperature fluctuations versus annual temperature fluctuation.
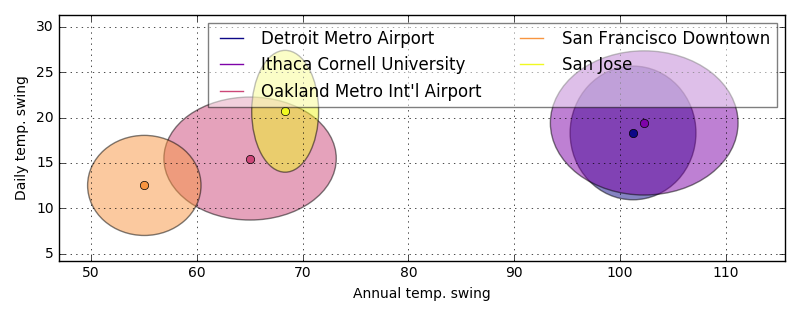
The first way I thought of to visualize this question was to look at a plot of 1:the difference between the daily highs and lows versus 2:the difference between the highest temperature in a year. I can measure the mean value and standard deviations of both of these quantities.
For each city, I’ve plotted the mean of the differences described above and the shaded ellipses show the standard deviation of the quantities.
One thing becomes very clear from this plot: there is something very different about Detroit and Ithaca compared to the Bay Area cities. I was surprised that the daily fluctuations for Oakland and SF were smaller than the ones in Detroit and Ithaca, but it is clear that they are still relatively large compared to the annual fluctuations.
This plot made me think that it might be interesting to not only try and compare the daily and annual fluctuations, but the fluctuations for timescales in between as well. The power spectrum of the temperatures can be used to measure these fluctuations across different time scales.
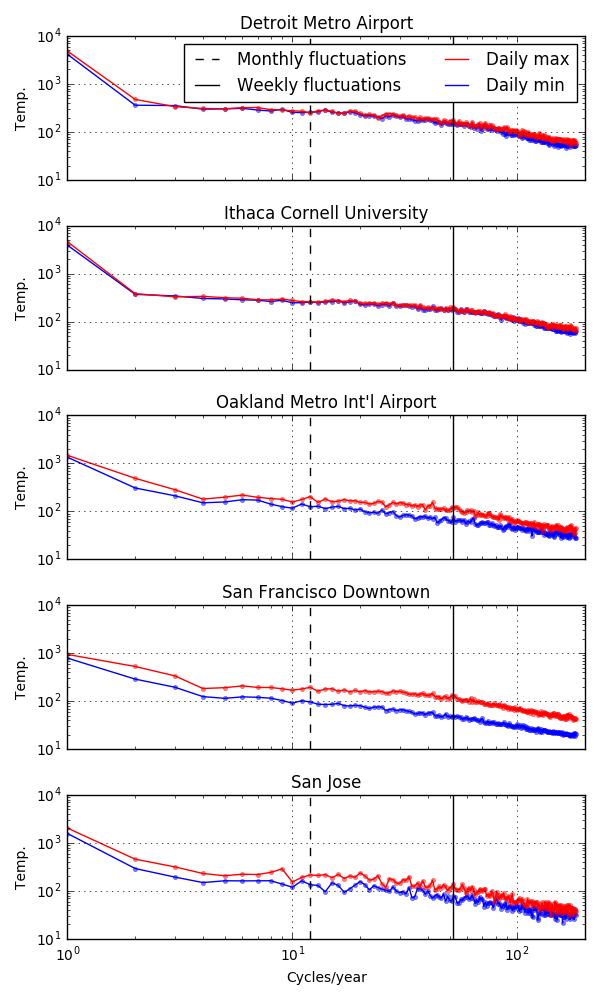
Annual temperature power spectrum for different cities.
The y-axis of this plot is proportional to the amplitude of the `temperature fluctuations at a given time scale. The x-axis are the different timescales (log-scale) from annual fluctuations on the left (1 per year), to day-to-day fluctuations on the right (365/2 per year). I’ve also marked the monthly and weekly fluctuations with the vertical lines.
I noticed a few things from these plots. For Ithaca and Detroit, the short-timescale fluctuations seem to be similar for the daily highs and daily lows and there is only much of a difference in the annual timescales (and maybe a little bit sub-weekly, I haven’t done any careful stats). In contrast, in the Bay Area there are noticeable differences between daily highs and lows across timescales which are pretty prevalent at about the week timescale. Detroit and Ithaca also have a large kink at 2 cycles/year which means that temperature fluctuations at annual timescales are much larger than any of the shorter timescales. For the Bay Area, it’s a much more smooth transition.
This still does quite answer the question I’m interested in, and there is one more analysis I’ll describe which, I think, gets at why the Bay Area weather is weird.
The weather in the San Francisco Bay Area is weird. At least it is weird compared to most of the other places I’ve lived in the US. In the suburbs of Detroit where I grew up and in upstate New York where I went to college, you could be comfortable in the same clothes basically all day or night. If you’ve ever been to the Bay Area, you know that this is not true. It can be in the 50s in the morning and evening and then 80 during the day.
So, I’ve always thought that the Bay Area must have larger daily temperature swings relative to the seasonal swings compared to other places I’ve lived. I wanted to find some historical data to look at this phenomenon and finally found it at the National Oceanic and Atmospheric Administation (NOAA) website, which has a nice search function for different databases.
I finally got around to downloading some data for cities that I’ve lived in or near. I’ll write a few posts looking at the data and also exploring different ways of visualizing the data.
You can find the analysis and plotting code I’m writing on my github here. It’s a work in progress, so there’ll be more updates and cleanup.
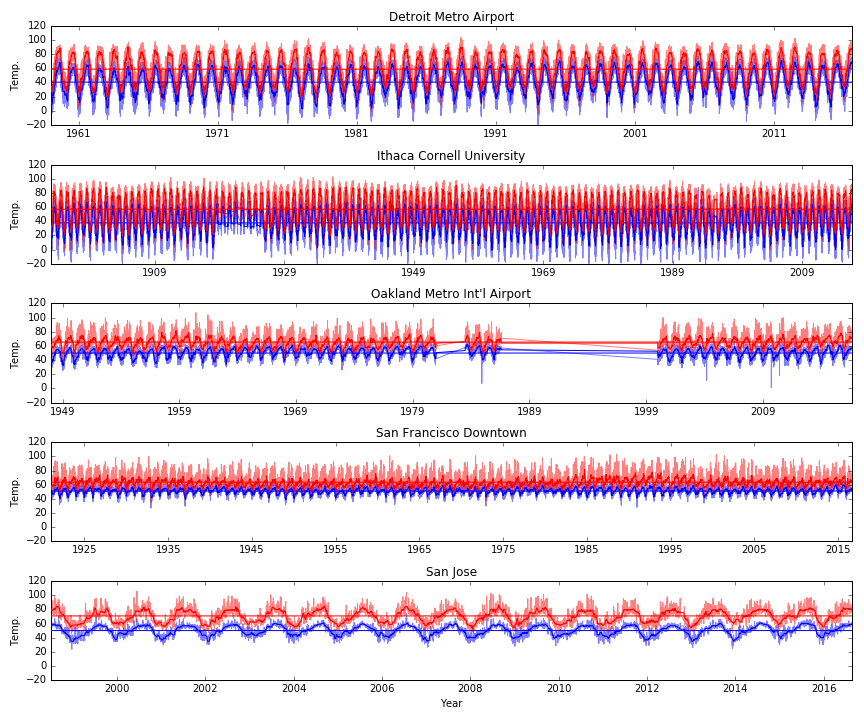
This first post is basically just trying to take a broad look at the data. So, first I just want to plot all of the data for each city. Click on the plot for a larger version. The first plot as the daily high (red) and daily low (blue) along with a local median filtered version (darker squiggly line) and the average over all time (darker straight horizontal line) for the high and low temps. The y-axes are all the same, but notice that the x-axes have different numbers of years.
From this plot I noticed a few things. Different cities have very different annual temperature swings. But, some cities have much larger separation between the daily minimum and maximum. In fact, for San Jose, it looks like the daily swings are almost as large and the annual swings!
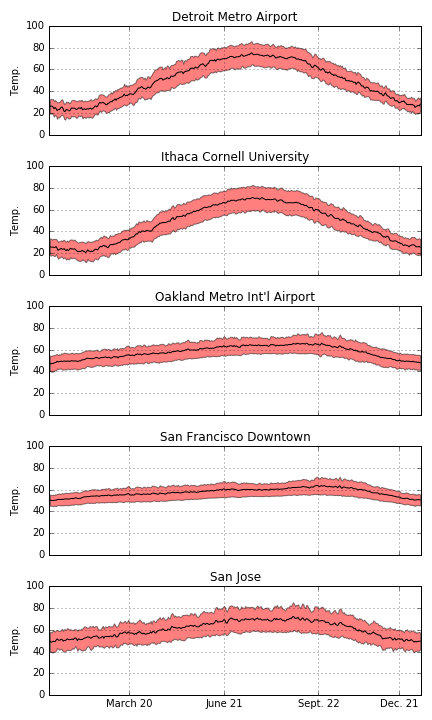
We can also look at the data where we take the average for a year. These plots show the daily average maximum and minimum temperatures (top and bottom of red shaded area) and the halfway point (black line). Again, we can see that some cities have large annual swings (Detroit and Ithaca) and the Bay Area has a relatively small annual swing. In the next post, I’ll do a more careful comparison of the daily and seasonal swings!
Machine learning is a broad set of techniques which can be used to identify patterns in data and use these patterns to help with some task like early seizure-detection/prediction, automated image captioning, automatic translation, etc. Most machine learning techniques have a set of parameters which need to be tuned. Many of these techniques rely on a very simple idea from calculus in order to tune these parameters.
Machine learning is a mapping problem
Machine learning algorithms generally have a set of parameters, which we’ll call $$\theta$$, that need to be tuned in order for the algorithm to perform well at a particular task. An important question in machine learning is how to choose the parameters, $$\theta$$, so that my algorithm performs the task well. Let’s look at a broad class of machine learning algorithms which take in some data, $$X$$, and use that data to make a prediction, $$\hat y$$. The algorithm can be represented by a function which makes these predictions,
\( \hat y = f(X;\theta)\).
This notation means that we have some function or mapping $$f(.; \theta)$$ which has parameters $$\theta$$. Given some piece of data $$X$$, the algorithm will made some prediction $$\hat y$$. If we change the parameters, $$\theta$$, then the function will produce a different prediction.
If we choose random values for $$\theta$$, there is no reason to believe that our mapping, $$f(.; \theta)$$, will do anything useful. But, in machine learning, we always have some training data which we can use to tune the parameters, $$\theta$$. This training data will have a bunch of input data which we can label as: $$X_i,\ i \in 1,\ 2,\ 3,\ldots$$, and a bunch of paired labels: $$y_i,\ i \in 1,\ 2,\ 3,\ldots$$, where $$y_i$$ is the correct prediction for $$X_i$$. Often, this training data has either been created by a simulation or labeled by hand (which is generally very time/money consuming).
Learning is parameter tuning
Now that we have ground-truth labels, $$y_i$$, for our training data, $$X_i$$, we can then evaluate how bad our mapping, $$f(.; \theta)$$, is. There are many possible ways to measure how bad $$f(.; \theta)$$ is, but a simple one is to compare the prediction of the mapping $$\hat y_i$$ to the ground-truth label $$y_i$$,
\( y_i-\hat y_i \).
Generally, mistakes which cause this error to be positive or negative are equally bad so a good measure of the error would be:
\(( y_i-\hat y_i)^2 =( y_i-f(X_i;\theta))^2\).
When this quantity is equal to zero for every piece of data we are doing a perfect mapping, and the larger this quantity is the worse our function is at prediction. Let’s call this quantity summed over all of the training data the error
\(E(\theta)=\sum_i( y_i-f(X_i;\theta))^2\).
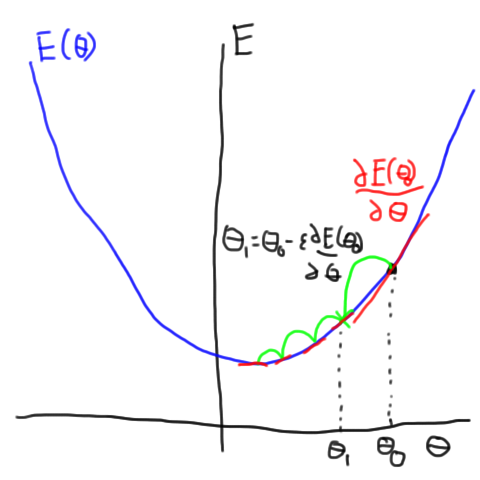
So, how do we make this quantity small? One simple idea from calculus is called gradient descent. If we can calculate the derivative or gradient of the error with respect to $$\theta$$ then we know that if we go in the opposite direction (downhill), then our error should be smaller. In order to calculate this derivative, our mapping, $$f(.,\theta)$$, needs to be differentiable with respect to $$\theta$$.
So, if we have a differentiable $$f(.,\theta)$$ we can compute the gradient of the cost function with respect to $$\theta$$
where $$\epsilon$$ is a small scalar. Now, if we repeat this process over and over, the value of the error, $$E(\theta)$$ should get smaller and smaller as we keep updating $$\theta$$. Eventually, we should get to a (local) minimum at which point our gradients will become zero and we can stop updating the parameters. This process is shown (in a somewhat cartoon way) in this figure.
If the error function is shaped somewhat like a bowl as a function of some parameter theta, we can calculate the derivative of the bowl and walk downhill to the bottom.
Extensions and exceptions
This post presented a slightly simplified picture of learning in machine learning. I’ll briefly mention a few of the simplifications.
The terms error function, objective function, and cost function are all used basically interchangeably in machine learning. In probabilistic models you may also see likelihoods or log-likelihoods which are similar to a cost function except they are setup to be maximized rather than minimized. Since people (physicists?) like to minimize things, negative log-likelihoods are also used.
The squared-error function was a somewhat arbitrary choice of error function. It turns out that depending on what sort of problem you are working on, e.g. classification or regression, you may want a different type of cost function. Many of the commonly used error function can be derived from the idea of maximum likelihood learning in statistics.
There are many extensions to simple gradient descent which are more commonly used such as stochastic gradient descent (sgd), sgd with momentum and other fancier things like Adam, second-order methods, and many more methods.
Not all learning techniques for all models are (or were initially) done through gradient descent. The first learning rule for Hopfield networks was not based on gradient descent although the proof of the convergence of inference was based on (not-gradient) descent. Infact, it has been replaced with a more modern version based on gradient descent of an objective function.
In Part 2, we adapted three tools developed for vectors to functions: a Basis in which to represent our function, Projection Operators to find the components of our function, and a FunctionRebuilder which allows us to recreate our vector in the new basis. This is the third (and final!) post in a series of three:
We can apply these tools to two problems that are common in Fourier Series analysis. First we’ll look at the square wave and then the sawtooth wave. Since we’ve chosen a sine and cosine basis (a frequency basis), there are a few questions we can ask ourselves before we begin:
Will these two functions contain a finite or infinite number of components?
Will the amplitude of the components grow or shrink as a function of their frequency?
Let’s try and get an intuitive answer to these questions first.
For 1., another way of asking this question is “could you come up with a way to combine a few sines and cosines to create the function?” The smoking guns here are the corners. Sines and cosines do not have sharp corners and so making a square wave or sawtooth wave with a finite number of them should be impossible.
For 2., one way of thinking about this is that the function we are decomposing are mostly smooth with a few corners. To get them to be smooth, we can’t have more and more high frequency components, so the amplitude of the components should shrink.
Let’s see if these intuitive answers are borne out.
Square Wave
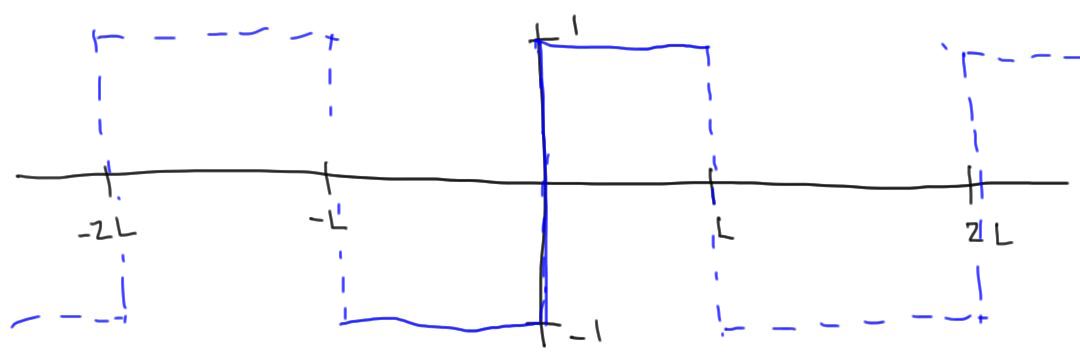
We’ll center the square wave vertically at zero and let it range from \([-L, L]\). In this case, the square wave function is
If we imagine this function being repeated periodically outside the range \([-L, L]\), it would be an odd (antisymmetric) function. Since sine functions are odd and cosine functions are even, an arbitrary odd function should only be built out of sums of other odd functions. So, we get to take one shortcut and only look at the projections onto the sine function (the cosine projections will be zero). You should work this out if this explanation wasn’t clear.
Since the square wave is defined piecewise, our projection integral will also be piecewise:
In Part 1, we developed three tools: a Basis in which to represent our vectors, Projection Operators to find the components of our vector, and a VectorRebuilder which allows us to recreate our vector in the new basis. This is the second post is a series of three:
We now want to develop these tools and apply the intuition to Fourier Series. The goal will be to represent a function (vectors) as the sum of sines and cosines (our basis). To do this we will need to define a basis, create projection operators, and create a functions rebuilder.
We will restrict ourselves to functions on the interval: \([-L,L]\). A more general technique is the Fourier Transform, which can be applied to functions on more general intervals. Many of the ideas we develop for Fourier Series can be applied to Fourier Transforms.
Note: I originally wrote this post with the interval \([0,L]\). It’s more standard (and a bit easier) to use \([-L,L]\), so I’ve since changed things to this convention. Video has not been updated, sorry :/
Choosing Basis Functions
Our first task will be to choose a set of basis function. We have some freedom to choose a basis as long as each basis function is normalized and is orthogonal to every other basis function (an orthonormal basis!). To check this, we need to define something equivalent to the dot product for vectors. A dot product tells us how much two vectors overlap. A similar operation for functions is integration.
Let’s look at the integral of two functions multiplied together over the interval: \([-L, L]\). This will be our guess for the definition of a dot product for functions, but it is just a guess.
\(\int_{-L}^Ldx~f(x)g(x)\)
If we imagine discretizing the integral, the integral becomes a sum of values from \(f(x)\) multiplied by values of \(g(x)\), which smells a lot like a dot product. In the companion video, I’ll look more at this intuition.
Now, we get to make another guess. We could choose many different basis functions in principle. Our motivation will be our knowledge that we already think about many things in terms of a frequency basis, e.g. sound, light, planetary motion. Based on this motivation, we’ll let our basis functions be:
\(s_n(x) = A_n \sin(\frac{n\pi x}{L})\)
and
\(c_n(x) = B_n \cos(\frac{n\pi x}{L})\).
We need to normalize these basis functions and check that they are orthogonal. Both of these can be done through some quick integrals using Wolfram Alpha. We get
This is a different convention from what is commonly used in Fourier Series (see the Wolfram MathWorld page for more details), but it will be equivalent. You might call what I’m doing the “normalized basis” convention and the typical one is more of a physics convention (put the \(\pi\)s in the Fourier space).
Projection Operators
Great! Now we need to find Projection Operators to help us write functions in terms of our basis. Taking a cue from the projection operators for normal vectors, we should take the “dot product” of our function with the basis vectors.
To recap, we’ve guessed a seemingly useful way of defining basis vectors, dot products, and projection operators for functions. Using these tools, we can write down a formal way of breaking down a function into a sum of sines and cosines. This is what people call writing out a Fourier Series. In the think post of the series, I’ll go through a couple of problems so that you can get a flavor for how this pans out.