In 2017, I ran a small set of experiments that asked the question: if the US Senate demographics were the results of a fair process, how (un)likely would the 2017 US be? Spoiler alert: not very likely to come from a fair process in 2017.
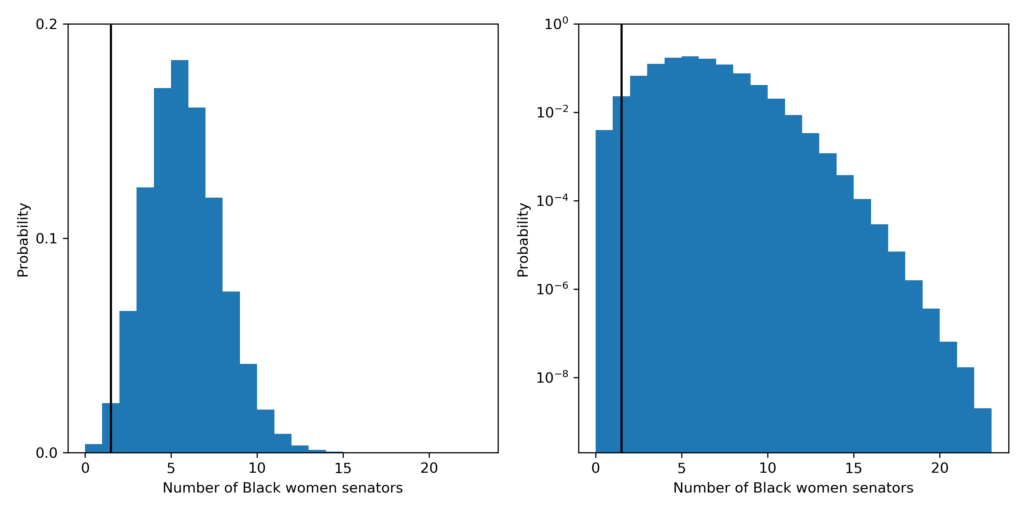
First, let’s look at what the probability is that a fair process produced a Senate with 1 or fewer Black women senators. The probability is about 2.7 in 100. The most likely outcome predicted by a fair process is 5 Black women senators which should happen 18% of the time.
The probability distribution for the number of Black women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black women: 1, in the Senate.
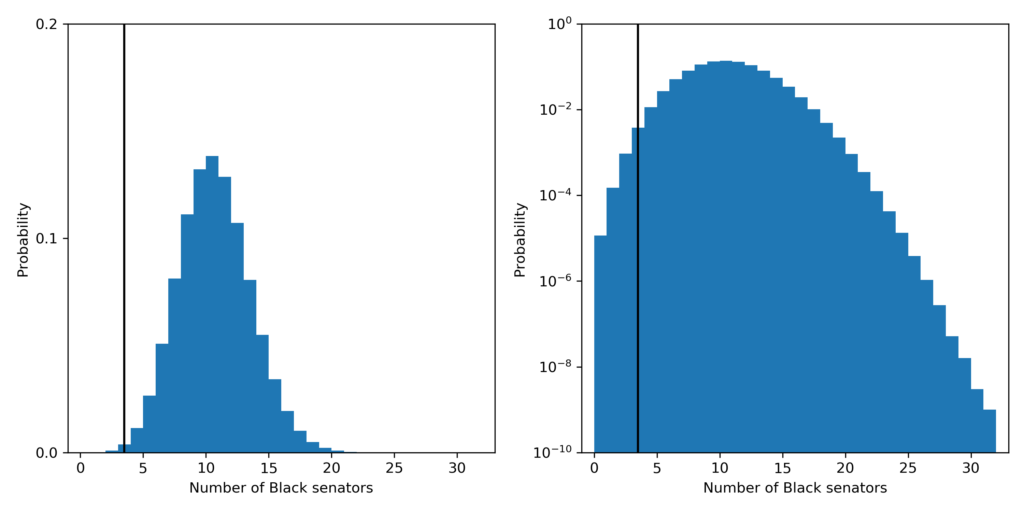
The probability that a fair process led to a Senate with 3 or fewer Black senators is about 4.9 in 1,000. The most likely outcome predicted by a fair process is 10 Black senators which should happen about 14% of the time.
The probability distribution for the number of Black senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of Black people: 3, in the Senate.
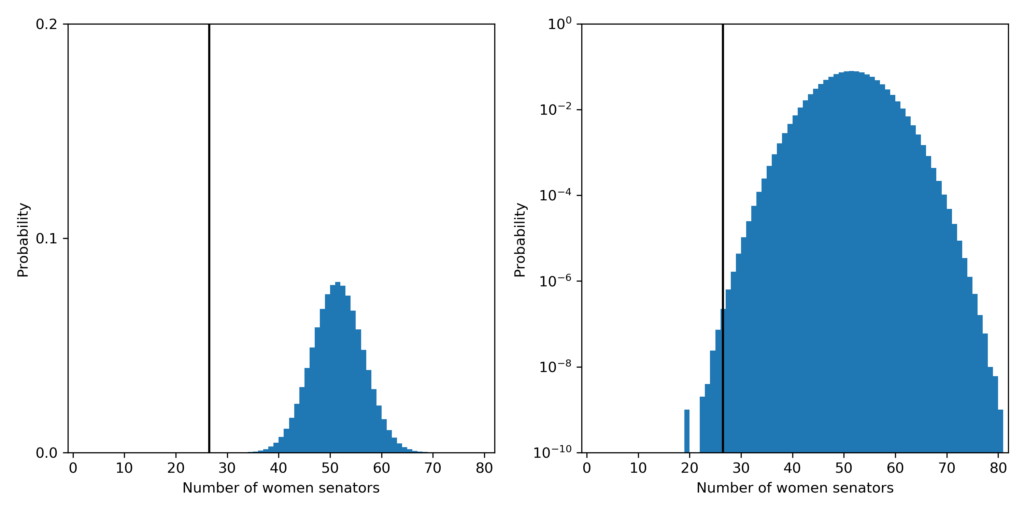
The probability that a fair process led to a Senate with 26 or fewer women senators is about 3 in 10,000,000! The most likely outcome predicted by a fair process is 51 women senators which should happen about 8% of the time.
The probability distribution for the number of women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of women: 26, in the Senate.
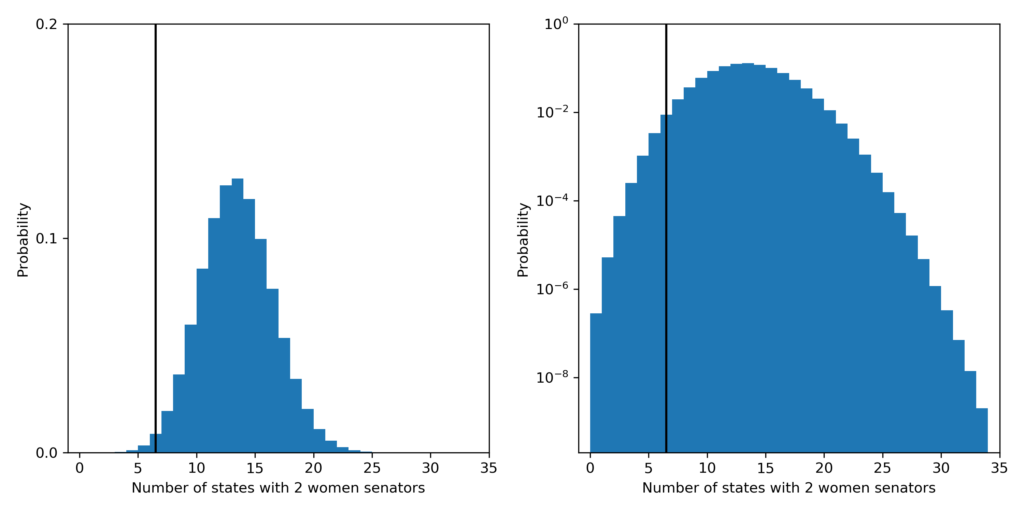
Finally, the probability that a fair process led to a Senate with 3 or fewer states with 2 women senators is about 1.3 in 100. The most likely outcome predicted by a fair process is 13 states with 2 women senators which should happen about 13% of the time.
The probability distribution for the number of states with 2 women senators under the fair model. Left plot is linear y-scale and right plots is log y-scale. The vertical black line shows the current number of states: 6, in the Senate.
So what’s changed? Broadly, this shows that becoming a US Senator is not a fair process. It it biased against non-Black women, Black people and Black women. The number of women has significantly increased, but is still not close to a fair fraction. The number of Black senators and Black women senators has not changed. Still more work to do!
You can find the data and code to reproduce these plots here.
Do we in the US still have the same Senate as it existed in 1790 (first census)? I’ll attempt to answer this question with regards to one particular attribute: the division of senators by percentiles of the population. Unlike the House, the Senate is not meant to represent states proportional to their population; each state gets 2 senators. When this system was created, the states had some distribution of large and small populations. Over time, the number of states and their populations have changed.
When the Senate was created, it was known that it would represent states but not individuals equally. This might be a reasonable system if the states’ populations are not too skewed [1]. It does become an obviously ridiculous system in the skewed limit. If a state lost enough residents such that its population became 2, it would be pretty bizarre to have them both as senators and have one senator represent one person’s vote. How skewed are we and has this changed since the late 1700s?
A simple way of answering this question is to break the US’s population into percentiles by how many senate votes they have. We’ll do this for four percentiles: 0-25%, 25-50%, 50-75%, and 75-100%. 0-25% percentile is the 25% percent of the population which has the largest fraction of a Senate vote, i.e. the 25% of the US population from the states with the smallest populations. This same process applies for the next 3 percentiles. If we know the population of the states [2] over time (available through the census), we can calculate the percentiles.
What does this look like for the 1790 through 2010 censuses?
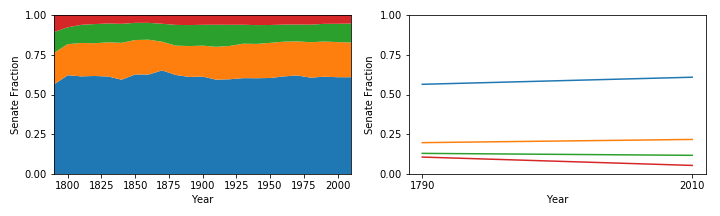
The plot on the left shows the four percentile divisions over time since the 1790 census. The plot on the right is lines connecting the fractions per division (not stacked) for 1790 and 2010 only.
The large blue area is the fraction of Senate seats going to the top 25% of the population (most Senate representation). It has hovered just over 60% of the Senate vote and has increased about 4% from 1790 to 2010 (much of that happened in the first decade).
The next orange and green areas show the next two percentiles which have increased by 2% and decreased by 1% respectively.
The small red area is the fraction of Senate seats going to the bottom 25% of the population (least Senate representation). It has hovered around 5% of the Senate vote and has decreased about 4% from 1790 to 2010 (much of that happened in the first decade).
This means that the top and bottom 25%s of the country currently have a 10x disparity in Senate representation.
And over time, the 50% of people who live in the smallest states, i.e. have the most Senate representation, have about 6% more voting power (equivalent to 6 more senators) in the Senate compared to 1790. Conversely, the 50% of people who live in the largest states, i.e. have the least Senate representation, have lost about 6% (lost 6 senators). I’ve rounded to whole numbers, so things don’t exactly add up as I’ve presented.
Recent trends
These percentiles move around a lot in the first 100 years of the US and those trends probably are not still happening today. What about if we look at the last 50 years?
In the last 50 years, the 50% of the population with the most representation in the Senate (smallest states) have had no significant change in representation. The 25% of the population with the least Senate representation have lost about .2% of a Senate seat per decade and the 25% with the second least representation have gained about .3% of a Senate seat per decade.
So the two main conclusions are one: that there is a large degree of skewness (~10x) in Senate representation, and two: that this has been relatively stable except for the 25% of the population with the least Senate representation (largest states) which has lost about half of its representation since 1790.
Notes
[1] I’m not commenting here on whether having the Senate as a congressional body is or was a good idea, just whether that body has changed over time in this particular way.
[2] I’ve removed the enslaved population in states since they had no representation.
Code to reproduce these plots (and more!) can be found here.
The electoral college (EC) is the system used in the US to determine how individual’s votes for president get turned into the numbers that actually determine who becomes president. Each state and D. C. is allocated a number of electors based partially on the population of the state from the last census. The number of electors is equivalent to the number of senators + the number of representatives for each state (D. C. gets 3), see here for details about how the allocations are calculated.
I’ve heard people say that one of the things the EC does is prevent voters in the cities from dominating rural voters. This has always seemed a bit odd to me since, on its face, the allocation is just based on state populations and not demographics. So, I decided to look at the relationship between rural, urban, and total population and how they related to the number of electoral college votes. The code and data for reproducing the plots are here. This is all based on 2010 Census data.
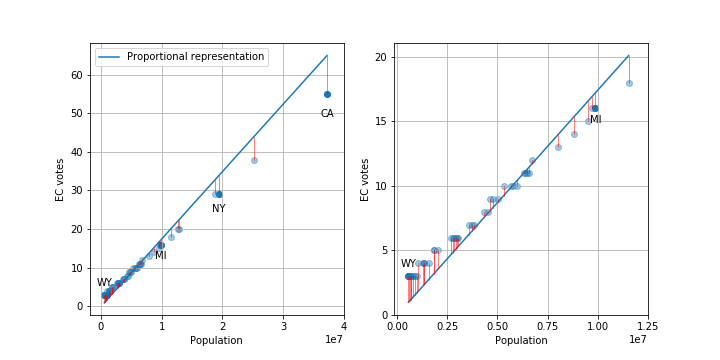
OK, first let’s just look at how many EC votes each state gets. There are a total of 538 electors. The plot below shows the distribution of votes for each state along with a line showing the number each state would be allocated if it was done exactly proportional to population. I’ve labeled a few states of interest.
Plots of the number of electoral college votes per state. Plot on the right in an inset of the bottom left corner of the plot on the left. Blue line is the number of votes states would have if the number of votes was proportional. The red vertical lines are the differences between the proportional number and actual number. (click to get larger version)
As you can see, states with smaller populations tend to have larger than proportional representation and larger states have fewer votes.
We can look at the number of electoral votes that different people get, i.e. how much is your vote worth in a presidential election. I’m leaving out a lot of important details, like racist voter suppression, the number of actual people able to vote in each state versus total population, and changes in population/demographics since 2010. Given the 538 electors and the 2010 population of 308,745,538, the average person gets. 1.7e-6 or 1.7 millionths of a vote. But, this will vary state-to-state based on the number of electors allocated to each state.
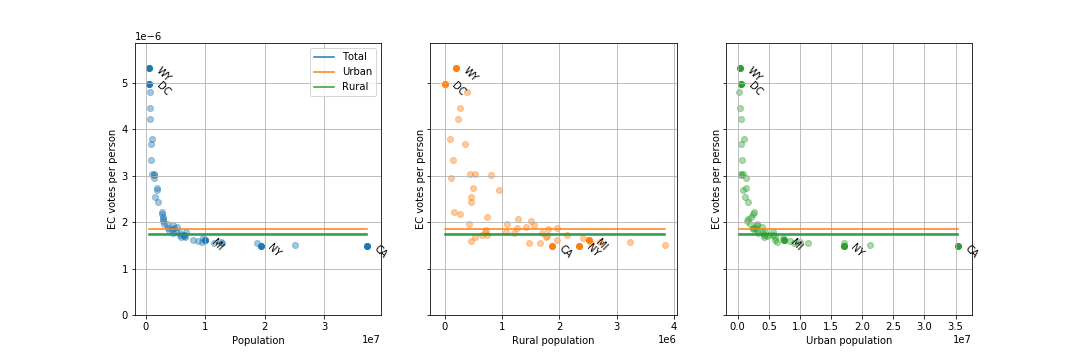
EC votes per person for different states and D.C.. Plotted against total state population, rural population, and urban population (rural and urban add up to total). (click to get larger version)
As you can see, the number of EC votes per person varies from about 1.5 millionths (California) to 5.3 millionths (Wyoming), about a factor of 3.5. State with populations above about 10 million all have similar EC votes per person, but small states can have much larger votes per person.
The solid blue line is the national average EC votes per person (1.74 millionths), the solid green line is the national average EC votes for someone living in a urban area (1.72 millionths, barely below the blue line), and the solid orange line is the national average EC votes for someone living in a rural area (1.85 millionths). So, on average, a person living in a rural area has about 8 percent more voting power compared to someone living in an urban area.
But!, the 601,723 people living in urban D. C. have 338 percent more voting power than the 1,880,350 people living in a rural area of California.
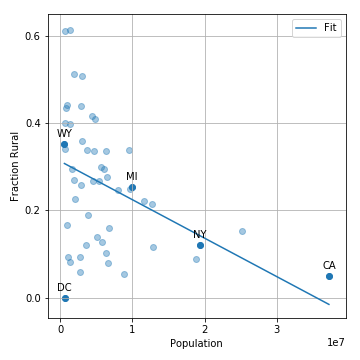
Finally, let’s look at how the total state population correlates to the fraction of people living in rural areas.
Fraction of population which lives in rural areas versus total population. There is a trend that states with larger populations tend to have a smaller fraction of people living in urban areas. For states with a total population less than than 10 million, there is much more variance in the fraction of people living in urban areas.
This shows that there is indeed a negative correlation, i.e. smaller states tend to have more people living in rural areas (this leads to the 8 percent difference above).
The thing that I take away from all of this is that the electoral college is actually weighting your vote as a member of the US lower than your vote as member of your state. Because of the current state demographics, it also weights rural votes slightly higher than urban votes, but this is a very small effect compared to the small state versus large state effect (8 vs. 350 percent). So, if you currently live in a big city in California, New York, or Texas and want your vote for president to have more impact, you’ll get more value for your vote if you move to an urban area in Wyoming, D. C., or Vermont rather than a rural area of your state, although you can still have an impact on House and state reps within your state.
I should also note that all of this analysis misses a larger problem of the electoral college: most states have a winner-take-all system where the candidate with the popular majority takes 100 percent of the electoral votes. This means that a candidate who wins 51 percent of the votes in a state gets 100 percent of the EC votes. This system is also used for state reps. and when coupled with gerrymandering, can lead to skews in the state representation compared to state voting demographics.
Edit: Thanks Dylan for catching some spelling errors!
The weather in the San Francisco Bay Area is weird. At least it is weird compared to most of the other places I’ve lived in the US. In the suburbs of Detroit where I grew up and in upstate New York where I went to college, you could be comfortable in the same clothes basically all day or night. If you’ve ever been to the Bay Area, you know that this is not true. It can be in the 50s in the morning and evening and then 80 during the day.
So, I’ve always thought that the Bay Area must have larger daily temperature swings relative to the seasonal swings compared to other places I’ve lived. I wanted to find some historical data to look at this phenomenon and finally found it at the National Oceanic and Atmospheric Administation (NOAA) website, which has a nice search function for different databases.
I finally got around to downloading some data for cities that I’ve lived in or near. I’ll write a few posts looking at the data and also exploring different ways of visualizing the data.
You can find the analysis and plotting code I’m writing on my github here. It’s a work in progress, so there’ll be more updates and cleanup.
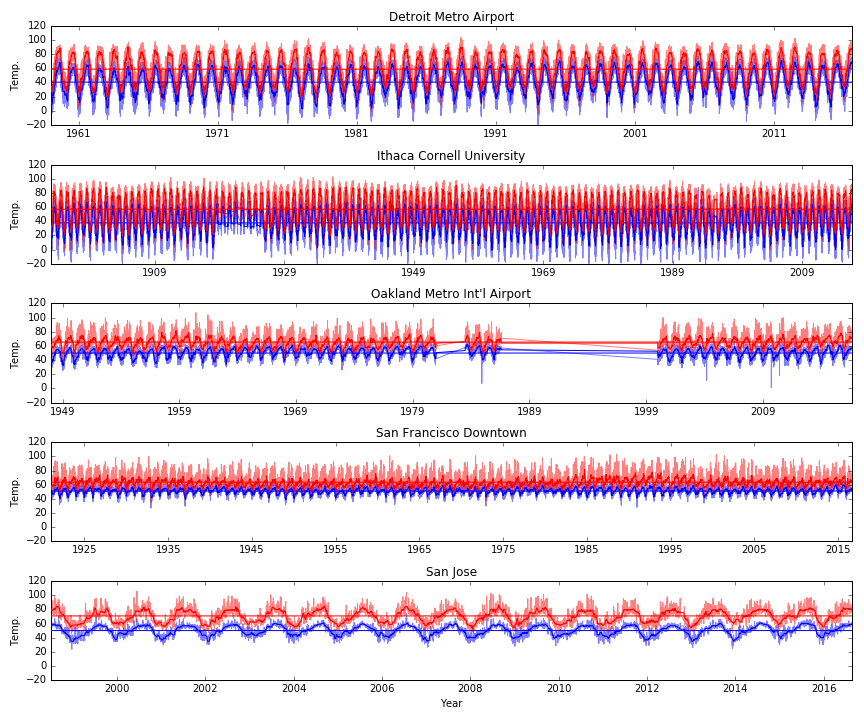
This first post is basically just trying to take a broad look at the data. So, first I just want to plot all of the data for each city. Click on the plot for a larger version. The first plot as the daily high (red) and daily low (blue) along with a local median filtered version (darker squiggly line) and the average over all time (darker straight horizontal line) for the high and low temps. The y-axes are all the same, but notice that the x-axes have different numbers of years.
From this plot I noticed a few things. Different cities have very different annual temperature swings. But, some cities have much larger separation between the daily minimum and maximum. In fact, for San Jose, it looks like the daily swings are almost as large and the annual swings!
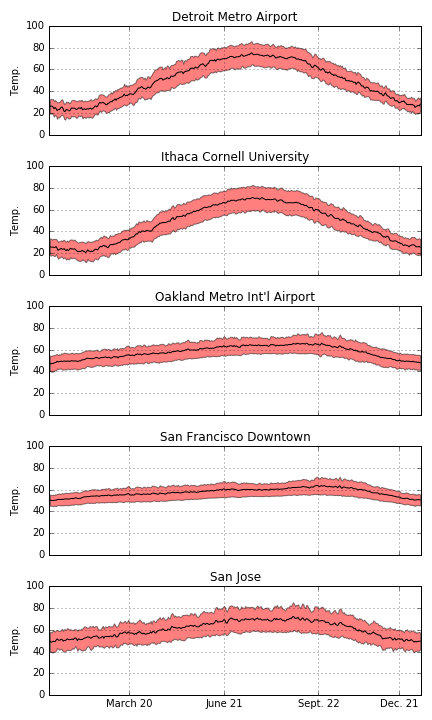
We can also look at the data where we take the average for a year. These plots show the daily average maximum and minimum temperatures (top and bottom of red shaded area) and the halfway point (black line). Again, we can see that some cities have large annual swings (Detroit and Ithaca) and the Bay Area has a relatively small annual swing. In the next post, I’ll do a more careful comparison of the daily and seasonal swings!